California Wildfire Prediction: Machine Learning
Beat the Heat is a project aimed at leveraging machine learning (ML) to fight wild fires in California. More specifically, data on conditions influential to fires were taken from raw sattelite images along with fire record data to train ML models to determine whether a fire was likely to take place given a set of conditions. These conditions include plant health, temperature of the surface of the earth, and a fire detecting factor called thermal anomalies, and were matched against the fire record to train our models of what senarios are likey to result in fires. A number of ML models were used on different combinations of the data, with the most noteworthy accuracy results being 93% and 86% with support vector machine and k-nearest neighbor models, respectively. For a more detailed description with diagrams, please go to the design page or read the full paper here.






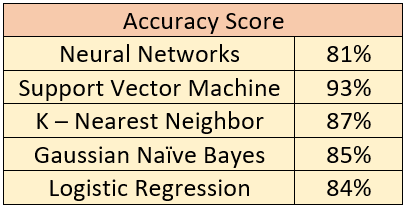
Figure 1 shows the results of the different machine learning models we have used to analysis the fire conditions across all of California. As shown in the table above, the Support Vector Machine (SVM) had the highest accuracy score of 93% in predicting wildfires in California. In order to increase the practicality of this project, the dataset inputs were broken down further into counties. This meant the models would attempt to predict fires in certain counties rather than what conditions were likely to cause fires in California, as the original experiment modeled.
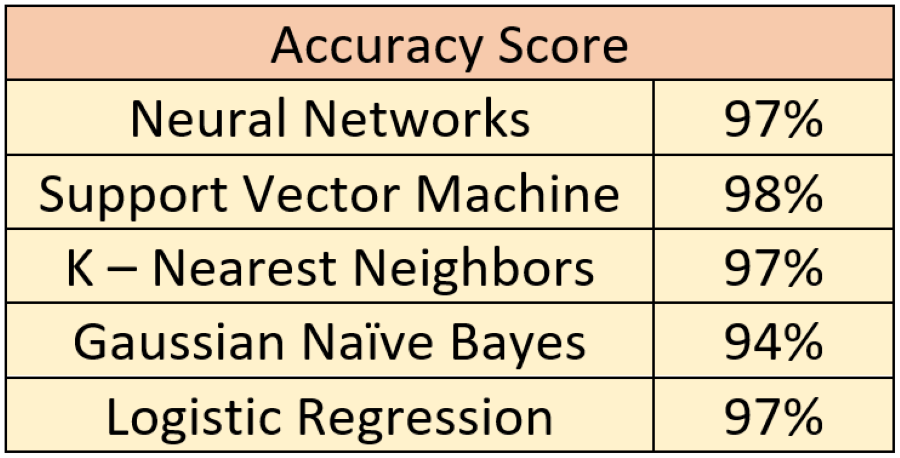
Figure 2 shows the result of all models applied on the data of 44 counties CA that had fires in the past two years. Even though this result is very high accuracy score but it might be too biased due to the imbalance class in the data. There were 1370 Fires and 41,028 No_Fires. The ratio is approximately 1:30 and is considered a severe imbalance. This imbalance could lead the model to predict on only No_Fire most of the time.