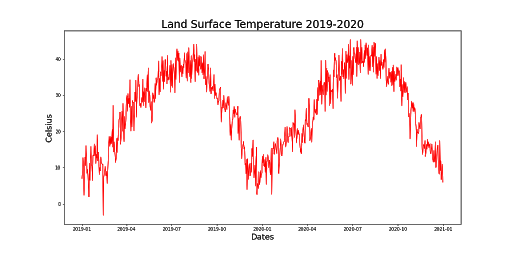
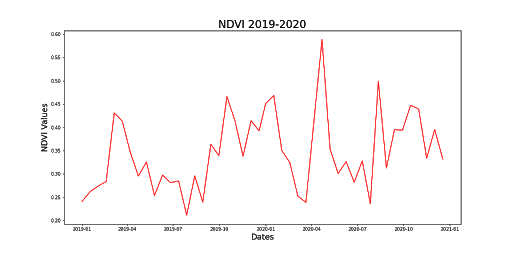
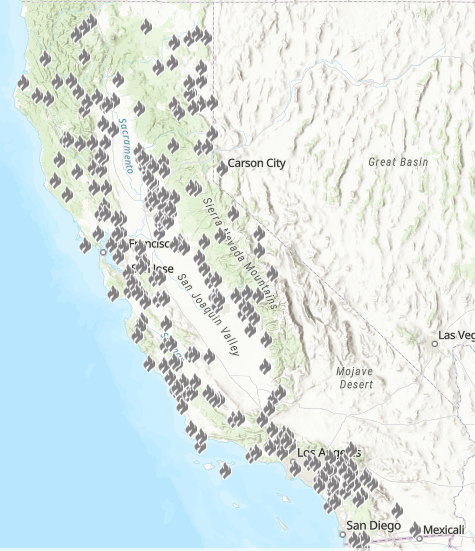
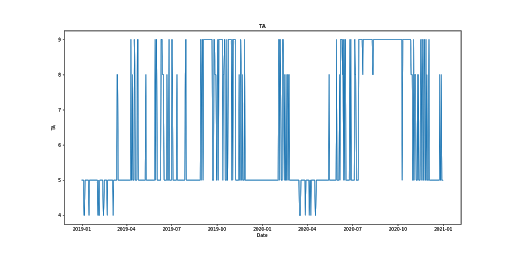For this project, there were 5 datasets that were used to train the machine learning models: Land Surface Temperature (LST), Normalized Difference Vegetation Index (NDVI), Burned Area (BA) and Thermal Anomalies (TA), California Fire Incident Report and the California City and County Boundaries datasets.
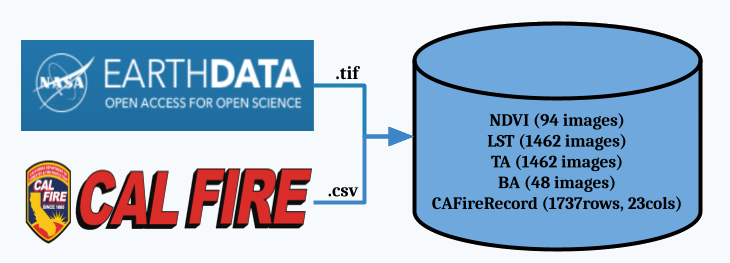
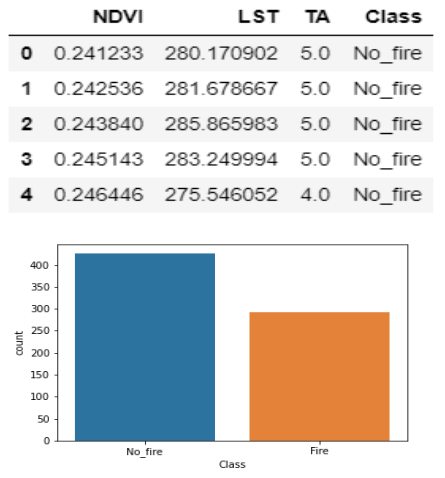
The LST, NDVI, BA, and TA are datasets that are created using Moderate Resolution Imaging Spectroradiometer (MODIS), or satellite, data. After preprocessing the four MODIS datasets, the BA was used as a mask to target fire and no_fire regions, to extract the LST, NDVI and TA values from those regions. Then the fire and no_fire classifications were extracted from the California Fire Incident Report, combined with the LST and NDVI datasets and finally the combined dataset was utilized to train the models to predict fire or no_fire.
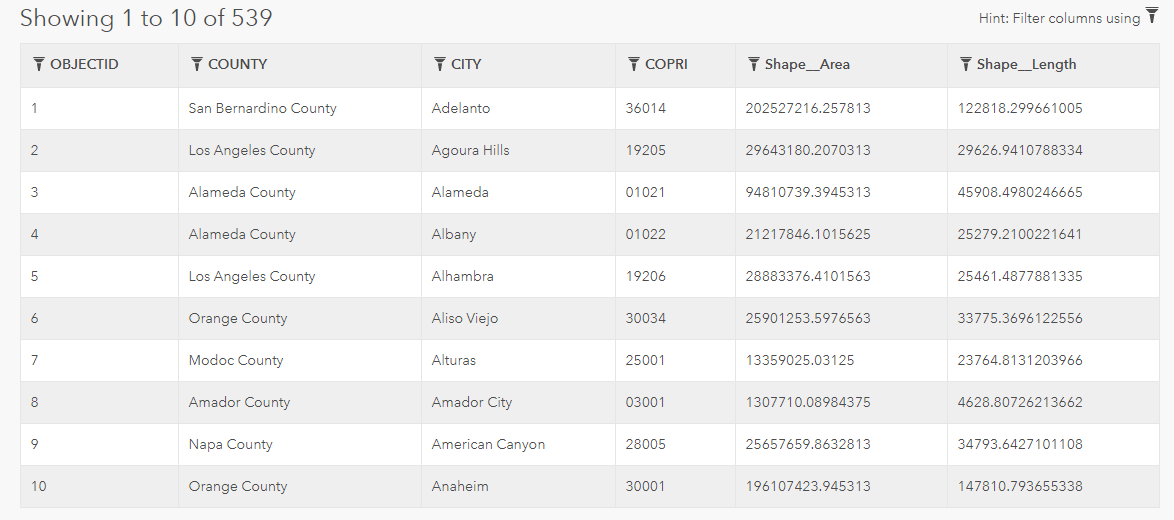
When the datasets were structured based on the California county data, the BA mask was not utilized. Instead the counties acted in a similar fashion as the BA dataset, and were used to extract the LST, NDVI and TA values based on the county regions. Then the combined datasets were used to train new models based on the county dataset.