Energy Benchmarking
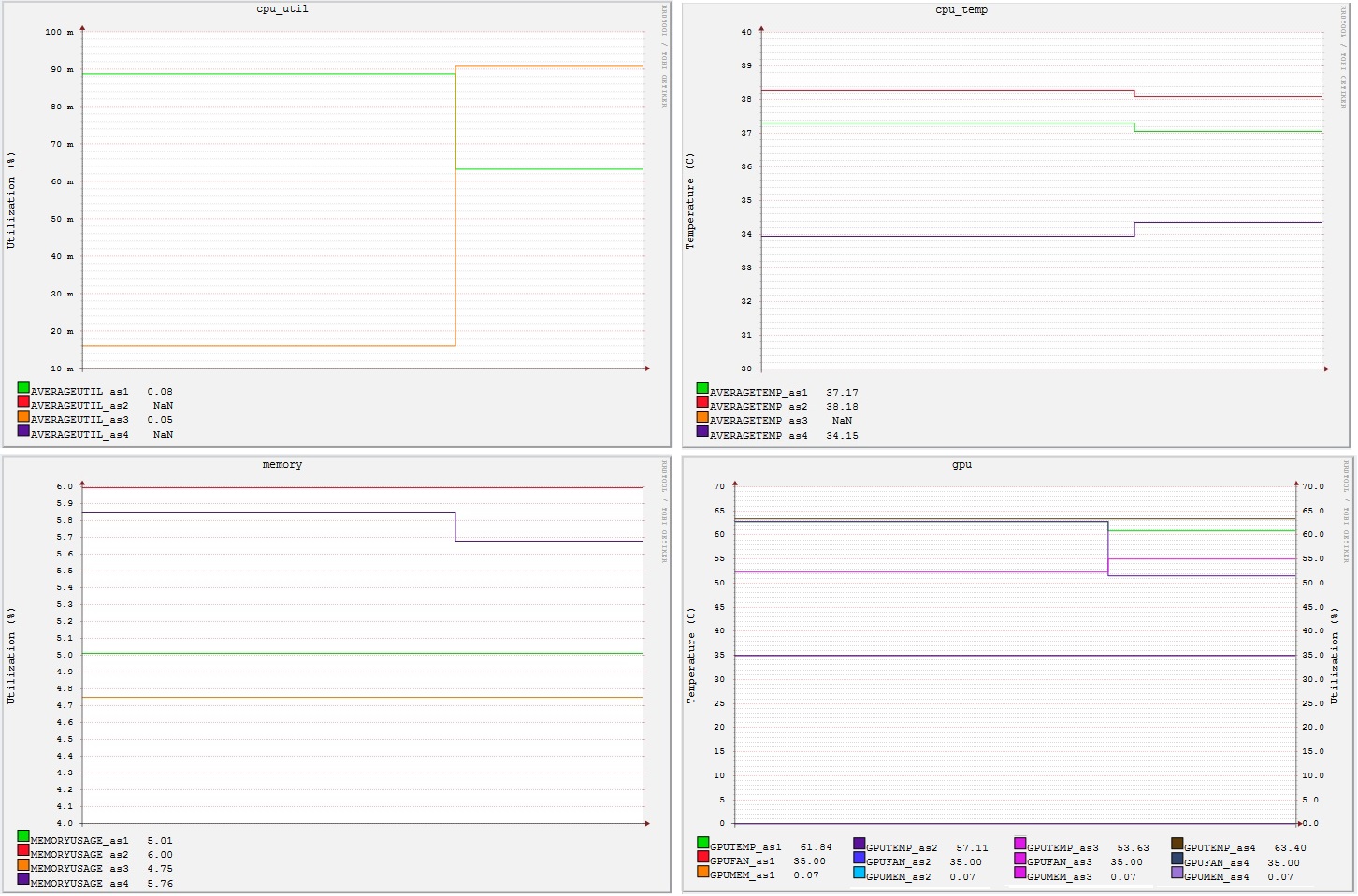
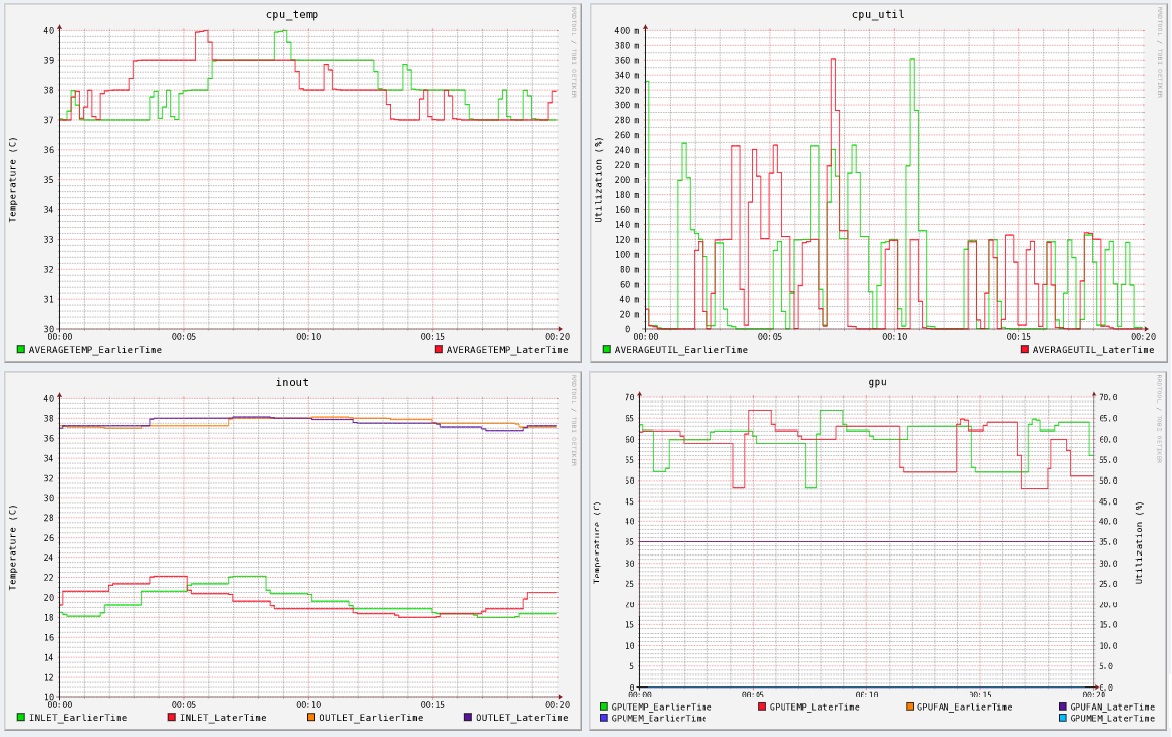
Benchmarks were used to study the power consumption and heat generation of our new cluster Whedon under various workloads. An array of 19 temperature sensors and a base unit were used to track the temperature of the air entering and exiting each computing node and the ambient temperature in the cluster room. We used Whetstone to simulate intensive workloads on the cluster’s central processing units (CPUs) and PostMark to create heavy loads on the cluster’s disks. We found a much clearer correlation between CPU utilization and energy use than with disk use. In addition, we run benchmarks (i.e., sort, wc, grep) to study how Hadoop worked to dispath tasks.
(Figure created by Eli Ramthun.)
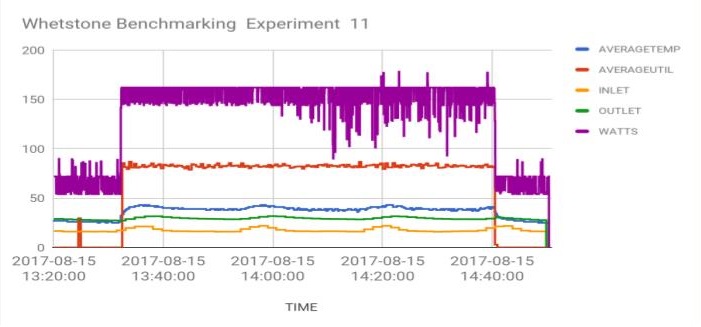 |
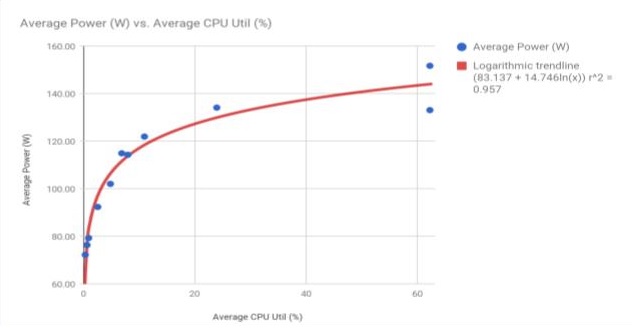 |
| Figure 1. Raw data from one of the Whetstone benchmarking trials executed on Whedon | Figure 2. Experimental results from 11 trials of Whetstone benchmarking on Whedon produced a clear logarithmic relationship between power drawn and CPU utilized. |
In order to study how various load balancing techniques affect the power and total energy consumption, we designed experiments to compare sorting very large data files with two different workload distribution systems: (1) Hadoop, an open-source framework for large-scale distributed computing; (2) TORQUE, a resource management system for scheduling batch tasks.
We conducted a group of experiments using Hadoop's example benchmarks such as Grep, Sort, WordCount, and MultiFileWC to see how Hadoop handles different number of tasks, and how many Mapand Reduce tasks are assigned to nodes for each data set. We run the MultiFileWC for several times, including experiements that diferent number of files with the same size were used as the dataset, and files with the same total file size but differnt number of files. The experimental results could be found in the following figure.
(Figure created by Phuc Tran Hoang.)
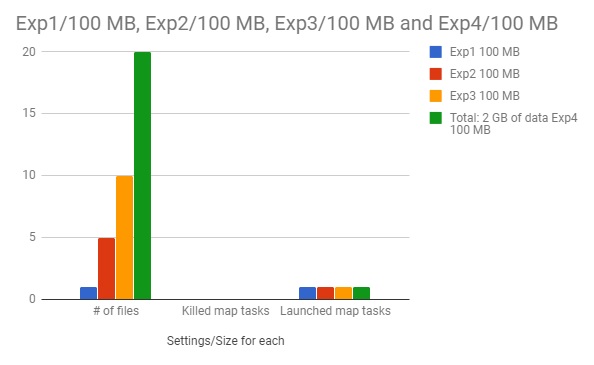
Figure 3. Experimental result of running MultiFileWC benchmarks on Hadoop