CD 485 Computer Applications
in Communication Disorders and Sciences
Voice Input Computer Systems &
Programs
Section I
Identifying the appropriate caseload
Computers
have been popular in academia as a teaching tool particularly because of their
capability to interact with the student.
Computers are even more compelling as a drill master when they can
respond to a human voice. Even the
old Apple II computers with the aid of a special card could respond to a human
command, but considerable time had to be taken to “teach” the
computer to recognize each
student’s voice and the number of commands the computer could understand
was limited.
Today’s
computers have considerably more capability to process a human voice
input. Word processors can respond
to thousands of words, which make them a valuable asset to visually impaired
students and professionals. The
same is true for those who have severe motor disabilities below the neck area.
For
individuals who have speech impairments voice input programs can meet two rehabilitative
needs. It can analyze and portray
a visual display of an individual’s speech and/or voice production so it
can be analyzed by the clinician and/or by the student; and it can provide
immediate visual feedback of a student’s speech and/or voice production
for practice purposes. The program
we have chosen to demonstrate these features is Speech Viewer.
This is a program that uses speech input to teach a number of speech
and/or voice concepts. It does not
teach language, however. Hence, it
would be suitable for individuals who are dysarthric, and/or apraxic but not
aphasic. It is particularly useful
also in working with hearing impaired individuals who want to develop or
improve their oral skills; and for students who wish to correct a foreign
accent.
The goals
and tasks of Speech Viewer
The
goals of Speech Viewer are to develop the following oral skills:
1) phonation
2) pitch
3) voicing
4) vowel
production
For
more, check out this Web site: http://www.auburn.edu/~fitchjl/spvw.txt
Unlike the
computer programs of the past, it is not necessary, when using Speech Viewer to teach the computer to
recognized the student’s (user’s) voice. The program accepts any voice and matches it to a criteria
sample to determine the correctness of the input; or the clinician can create
their own sample criteria. This
and the use of graphics, which respond to the voice input as feedback are
strengths that make programs like Speech Viewer a useful clinical tool
Section II
The Tasks of
Awareness in Speech Viewer
We
are referring here to the original Speech Viewer version which we use and have
found quite adequate. There are, however, newer versions (Speech Viewer II, and
III, for example) which are available and, hence, will differ in some respects
from our demonstrations.
The Main Menu: The Speech Viewer
program (our original version) is divided into a number of main Tasks. These,
as seen on the Main Menu, include Awareness, Skill Building and Patterning.
The
Awareness
Goal includes the following sub tasks: Sound, Loudness, Pitch, Voicing Onset and Loudness and Voicing.
The Awareness of Sound: When you highlight
this task heading in the main menu and hit the “Enter” key, you
come to a fairly blank screen. But when you turn on the microphone and give a
sustained tone, a colorful collage appears on the screen. It remains there
(continuously changing in shape) until you stop phonating. At that point the
number of seconds duration of the unbroken phonation (to the closest tenth of a
second) appears in the lower right hand corner of the screen. Unfortunately, if
there is any sound at all following the end of the phonation, it erases this
score and a new count begins. This can happen if there is a break in a person's
voice as they reach the end of their breath support or if someone near the
microphone makes a noise. Barring this event, this number provides a goal
against which a person can try to improve their score. This gives an element of
sportsmanship or challenge to the activity. For example, I once worked with a
severely hard of hearing teenager who hated to phonate. He did however, enjoy
immensely the challenge offered by this activity and spent many sessions phonating
and enjoying it. Basically, then, this task provides visual feedback for
phonation.
If
you forget the instructions of this or any other task, the key "F1"
on the keyboard will take you to an instruction screen. If you want to leave
any screen -- hit the escape key.
The Awareness of Loudness: When you open the
Loudness task from the main menu, the screen will open with agraphic of a
string. When you phonate into the microphone a red balloon will grow at the end
of thestring. This provides feedback as to loudness. How it is used depends
upon your creativity. It couldbe used to sustain a loud voice; or it could be
used to sustain a soft voice; or it could be used toalternate between the two
etc.
The Awareness of Pitch: When you open the Pitch
task from the main menu, the screen will open with a graphic of a thermometer
with stationary frequency hatch marks on the right side. Two more hatch marks
on the left side, however, move when someone speaks into the microphone, to
indicate the highest and lowest pitches detected during the vocalization. When
you talk into the microphone, the red center of the "thermometer"
also rises and falls with the pitch. Together they give a visual feed back for
the pitch level at any particular moment, and for the overall pitch range. The
left hand hatch marks can be readjusted to the center position by hitting the
space bar. Remember, to hit the F1 key for instructions and the Escape key to finish and return to the
main menu.
The Awareness of Voicing Onset: When you open the
Voicing Onset task from the main menu, the screen will open with a graphic
picture of a train. When you start to vocalize, the train will move forward a
short distance. When you vocalize again, the train will move again. A sustained
tone, however, does not result in continued movement. A harsh glottal attack
will also fail to move the train. The task is to move the train to the end of
the track. There is a timer (in seconds) in the lower right hand corner, so
that feedback is available and goals can be set. This is excellent practice for
pupils who have problems initiating voice; and for those who have glottal
attack problems, flaccid dysarthria, and even spasticity (when used from the
frame of reference of relaxation).
The Awareness of Loudness and Voicing: When you open the
Loudness and Voicing task from the main menu, thescreen will open with a
graphic picture of a clown. If you produce a consonant, the clown's mouth
willmove. The greater the intensity, the more the mouth moves. If you make a
vowel, the tie lights up withpolka dots. If you make a voiced consonant, both
the tie and the mouth are activated. This exercise is particularly good for
contrasting cognates, and for increasing the strength of consonants (particularly fricatives).
Section III
The Tasks of Skill
Building in Speech Viewer
The Skill Building Goals includes the following
four tasks: Pitch,
Voicing,
Vowel
Accuracy
and Vowel Contrasting. There is a fifth, called Model Setup, but this is for the
clinician's use only, and is not a task for rehabilitation. It's purpose is to
develop a personalized set criteria for voice comparisons between the pupil and
the computer (i.e.,
vocalizations
the computer will accept as correct).
Pitch:
This exercise is excellent for developing pitch control. It is especially good
for deaf and hard of hearing pupils, but is also excellent for individuals with
neurologically based pitch problems. When you open the Pitch task from the main
menu, the next screen will present a choice of icons (which would be equivalent
here, to a PAC man figure). You can choose a Camel, a Dolphin, a Motor Car (we
used this in the quicktime movie example), and others. When you have
highlighted your choice and pressed the enter key, the next screen will present
you with a menu of levels of difficulty. This is an excellent feature, which
permits you to fit the level of difficulty of the task to the level of
sophistication of the pupil. When the level has been selected, the next screen
appears with the field of action. On the field is the motor car (the icon we
selected) and some objects. We are to touch some objects (a gas can and some gas pumps) with the motor
car and to avoid others (some people, trees, and parking meters). The car moves
forward at the sound of phonation, and up or down with a raised or lowered
pitch. The pitch must be fluctuated smoothly in small to moderate to get the
best control of the motor car. If the pupil maneuvers through the maze without
bumping into the bad objects and at the same time touching the good ones, there
is a graphic display of sorts for a reward. By using the F1 key, instructions can be obtained and
parameters can be set. Parameters include for
example,
the level of the pitch range so it can better accommodate girls, boys or men
etc.
Voicing: This task is a
combination of phonation and voice onset control. When you have opened the
Voicing task from the main menu, the next screen will present two parallel
pathways. When you hit the space bar and begin phonating a line will be drawn
midway along the top path (the bottom path is just a continuation of the top).
If you stop phonating, the line drops to the bottom of the path forming what
appears to be a plateau outline. When you start phonating, the procedure is
repeated. You end up with a pattern of plateaus and troughs. When you hit page
down, this pattern is solidified and becomes the criteria for the student to
repeat. When they miss, a little buzzer is sounded. The task for the pupil
(client) then, is to practice turning on and off phonation at command, and/or
to be able to hold a tone for a designated period of time.
Vowel
Accuracy:
This task basically teaches vowel production. It is both one of the greatest
strengths and weaknesses of the system. It is a strength because vowel
production is one of the hardest things to teach, due to the lack of contact of
the tongue with any portion of the oral cavity during production. It is very
nice to have a
program
that makes it possible to receive visual feedback for vowel production. It is a
weakness, however, in that there is a lack of consistency in the feedback.
There are occasions when the pupil will produce the sound satisfactorily (by
human standards) and the machine will
give a negative feedback. Overall, the strength outweighs the weakness and this
task is very much worth using.
The
first screen, after selecting the task from the main menu, is a menu of voice
samples to chose from. Unlike the computer programs of the past, it is not
necessary, when using Speech Viewer to teach the computer to recognize the
pupil's (user's) voice. The program accepts any voice and matches it to a
criteria sample to determine the correctness of the input. The criteria sample
provided in the menu is from a Mid Western population. The clinician, however,
may have created a sample or samples herself/himself. For example, it may have
been desirable to have a sample criteria from the pupils family, or from the
age range, or from the culture etc. This is done in the Vowel Model
Setup task at the end of this Skill
Building section.
When
the voice sample has been chosen, the next screen presents a menu of vowel
sounds to work on. When one has been selected, a screen with a graphic
representation of a palm tree and two monkeys climbing it is presented. When the pupil tries to produce the
vowel, the lower monkey will push the upper one up the tree. The closer the
pupil's production is to the vowel sound criteria, the farther up the tree the
second monkey will be pushed. When the sound is correct, the second monkey will
reach the top and a coconut will fall.
Two numbers appear in the lower right
hand quadrant of the screen. One represents the "distance" the pupil's
production was off from the correct pronunciation of the vowel. The scale is
arbitrary but the numbers are useful for providing feedback and establishing
new short-term goals. The second represents the pupil's best score (closest
approximation).
The tolerance of the program to accept a
vowel production by the pupil as being correct can be changed along a continuum
from loose to strict. This provides the element of progression from the easy to
the more difficult task. This adjustment can be made by hitting the F1 key and
following the instructions. The Escape key, as always, takes us back to the
main menu.
Vowel
Contrasting:
Of all the tasks, this is, I believe, the most interesting for pupils at the
elementary grade age level. It basically drills vowel production and
discrimination. Its format is a maze (there are several levels of difficulty).
The task is to move the cursor through
the maze to the exit. Four vowels are selected and become the criteria, when
they are phonated, for the cursor to move in a specific direction. For example,
"ee" might move it right, "ah" left, "oo"
up , and "aw" down.
The first screen one sees after
selecting this task is a menu of criteria (speech production norms) including
the computer's sample of Mid Western pronunciation, and any personalized
samples the clinician has added. The screen after this presents a list of
vowels from which four must be selected. The Maze then appears on the screen.
The F1 key would be used if one wants further instructions, or wants to change
the difficulty of the maze; and as always the escape key closes the task and
brings back the main menu.
Section IV
Voice Patterns in
Speech Viewer
Voice
Patterning
goals include three tasks that are more suitable for older clients (junior high
through adult). They include Pitch and Loudness, Waveform, and Spectra.
Pitch
and Loudness:
When this task is selected, a screen is presented having two parallel grids,
one for the top half and one for the bottom of the screen. The top half can be
use for practice, but it can also serve as a model for a pupil to follow. When
you articulate a word, a graphic representation of that word appears on the
grid.
Consonants are displayed as a green zone
and vowels as red. The intensity of each is displayed by the width of the zone.
Hence the graph easily reflects the volume of the phoneme production,
especially as it relates to the differences between consonants and vowel
juxtapositioned in a word. The instructor can provide a model on the top half of
the screen by using the page down key after his/her production is
represented. The graphic
representation is preserved and the students attempt is displayed in the bottom
half of the screen. The space-bar is used start the process each time a new
word is to be recorded.
Speech
Viewer comes with an audio speaker for speech output. This task, Pitch and
Loudness, uses that feature. If you press the F9 key you will hear the pupil's
speech played back. By using the page up key and pressing F9, you
can
hear the model version of the instructor.
Waveform: This is a particularly
interesting task that I believe is very useful for working on prosody
(especially inflection and stress). For this task the monitor is divided into
two parallel displays. The top one provides feedback regarding the intensity of
the production (stress) and inflection variations. The former is displayed as a
solid curve
and
the latter as a red line over that curve. The key F9 will provide an auditory
feedback.
The
bottom half of the screen provides an in detail graphic representation of the
vocalization. This I believe is of more value to those interested in research
and is not so meaningful for rehabilitative purposes.
(Caution--Please note that in the
quicktime movie that follows, the example word used is "ship." With
all the frustrations that are associated with computers, one can easily
mistakenly hear a similar word of an expletive nature!)
Spectra: This is a curious task which provides a
wave form for a sustained vowel. By hitting the space bar while the vowel is
being phonated, the wave form is frozen on the screen. This can be repeated to
create a general wave pattern. The formants can be seen here relatively
clearly. By hitting the F5 key, vowels can be portrayed in different
colors.
I have found that this program is useful for encouraging adults to phonate in
general, and to discriminate more clearly in their production of different
vowels.
For further
information please explore the following Speech Viewer sites on the Web:
For pricing and
system requirements with Speech Viewer, check this Web site:
http://www.edmark.com/prod/sv3/
For information
about Speech Viewer for Windows, the Web address is:
For a demo disk,
the Web address is:
http://www.austin.ibm.com/sns/spv3demo.html
Section V
Video Voice
Another
voice input system for speech rehabilitation is Video Voice by Micro Video.
This system is perhaps even more intensive that Speech Viewer and has versions
that will work with either Macintosh or PCs! Basically, it is divided into 5 phases.
Phase 1: Fun & Games - Includes games and
graphic displays. There are formats for work on pitch and intensity in
isolation or in combination, duration, rhythm, onsets, stops, articulation, and
more. You can see how pitch changes affect the colors in Pitch Painting; and
watch boxes shrink and grow with volume changes in Magic Box; and use voicing
to move a train through the mountains, and similar activities.

In
some games, you can use stored models as targets for articulation practice or
define targets at game time. Most displays have entertaining animations and
sound effects to add to the fun. Many games have multiple goals and can be used
for more than one speech activity.
You can use Red Light-Green Light, for example, to work on pitch, volume or rate of speech. In Speech Ball, the goal can be simple
vocalization, onset, or voiced or voiceless sound production. Other games help develop pitch control,
learn appropriate volume levels, improve breath control, achieve vocalization on
demand, and produce articulation targets correctly.
Phase
II: P-A-R Displays (Non-Segmentals) – Video Voice's non-segmental displays
are cross-time representations of pitch and intensity. They are easy to interpret and can help
communicate a wide variety of information about speech, from basic phonation to
co-articulation and rate of speech.
The
P-A-R displays are valuable for communicating many "invisible"
aspects of speech: rising or falling pitch; loud vs. soft sounds; appropriate
inflection of words or phrases; volume variation; changes in cadence or rate;
duration of sounds; vocal stops; easy onset; continuous phonation; distorted
and natural voicing; and co-articulation of phonemes. You may choose either
pitch or volume as the primary characteristic in these cross-time displays,
with rhythm as a secondary element.
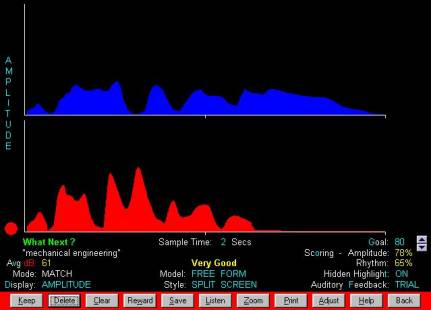
A
choice of voice sample-times from 1-10 seconds enables you to represent
individual sounds, words or connected speech with these displays. Although
initially presented in a direct overlay format, you may use the optional split
screen display to visually separate the model and trial for easy interpretation
of errors.
At
any time, you can instantly substitute an individual's voice and audio patterns
for the current model. Cartoon "stickers" reward good performance
against goals you define, and you may store scores for later review. P-A-R
models may also be used as the basis for the Fun & Games P-A-R Game Zone
options.
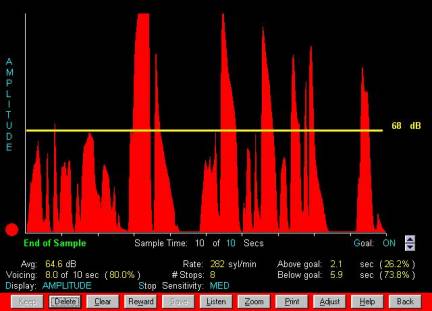
The
Connected Speech option is especially useful for fluency training or
reinforcing changes in habitual pitch. Sample times can be up to 15 minutes.
After sampling, Video Voice reports the average pitch used, or quantifies
fluency in number of stops, percentage vocalization time and speaking rate
(syllables/minute).
Phase
III: Formant Displays (Articulation) - Video Voice's Formant Displays help train
vowel production and various other aspects of articulation, both at the word and
connected speech levels. Therapy applications include vowel training,
voiced/voiceless phoneme discrimination, gross sibilant production, and sound
omissions, distortions and substitutions.
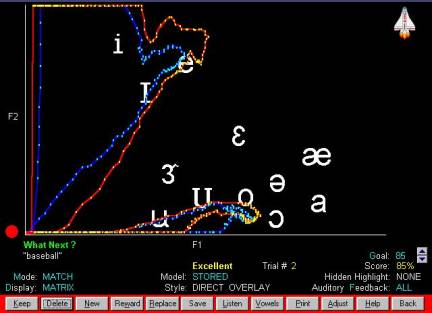
In
Video Voice's "F2 vs. F1" matrix display, isolated vowels appear in
general regions of the screen…

…and
words have shapes determined by their phonemic components. All models are
clinician-defined, so you determine the program content and select appropriate
therapy targets for each individual in your caseload.
The
matrix Formant Display can be used in two ways. In the Practice format, the
goal is to match the model pattern. The model and trial appear on the screen
simultaneously for easy analysis of similarities and differences, with
"instant replay" for review as needed. With click of the mouse, you
can change models "on-the-spot" to let individuals practice against
their own voice patterns. The other matrix display format, Gobble, is an
"eat-the-dots" style game that takes the boredom out of drill work
and encourages repeated production of targets. Its live feedback also
stimulates vocal play and helps speakers find and maintain appropriate
articulator positions for vowel and other sound production.
The
Temporal Display's cross-time representation of the formant frequencies assists
in remediation of durational articulation errors and offers a way to practice
segmental targets in a connected speech framework. The Formant Displays have numerous therapy applications.
Auditory feedback reinforces all visual displays, letting speakers both see and
hear their productions. You can also use cartoon graphics to reward good
performance in all displays. Some displays offer scoring against a
therapist-defined goal, with selective storage of scores for later review.
Phase
IV: Assessment Displays (Hz/dB Measurement) - The research/diagnostically-oriented
Assessment Displays actually quantify pitch and intensity levels in a speech
stream. These cross-time pitch/intensity displays can help you evaluate the
effects of training with the other Video Voice display formats.

Video
Voice's Assessment Display captures and quantifies the pitch and intensity
characteristics in speech. Sample times are adjustable (1-8 seconds), and a
windowing (Zoom) feature lets you restrict the high, low and average Hz and dB
readings reported to a selected part of
the sample. You may alternate between the combined, full screen display
and split screen presentations of either pitch or intensity as desired.
These
displays can help you gauge results achieved with the other Video Voice
displays. You may store samples, including auditory components, for reuse in
subsequent sessions or to provide a baseline for comparison with future
assessments. As with other Video Voice displays, you can print the graphic
patterns and related tabular report to use as supporting documentation for
insurance providers, IEP mandates or other institutional requirements. You may
even personalize the printed copy with your own commentary.
Phase
V: Record-keeping and Reporting - The Reporting and Analysis features let you
access saved score data to review performance in a single session or assess
progress over time. Tabular or graphic reports can be displayed on the screen
or printed, and you may add your own commentary as desired to support the data.
Video
Voice offers several options for preserving and analyzing the results of
therapy sessions. You can print both on-screen images and data collected, in
several report formats. Options include: On-the-spot screen copies; Single
session score reports; Cross-session score analyses (tabular and graphic);
Assessment (Hz/dB) displays and quantified data; and IEP/Therapy Plan
goal/objective summaries

You control the general content and format of
most reports, telling Video Voice to make them as simple or detailed as you
wish.

Select from tabular reports of high, low and
average scores against defined performance goals or bar charts that represent
progress graphically. In addition to standard information Video Voice provides in
its various report structures, you can add your own commentary to increase the
report's historical or personalized, "take-home" value.
Phase VI: Data Management - The Data Management
functions simplify individual record-keeping, caseload data handling, and the
creation and management of "model libraries".
With
Video Voice's Data Management functions, managing the information that it keeps
for your caseload is easy. These options let you:
|
Transfer data between files Remove outdated models, scores or cases Update information on your cases Use and manage model libraries Produce IEP goal/objective summaries Print model, session or caseload directories |
By creating libraries of models you frequently
use in therapy, you can quickly and easily set up directories for individuals
in your caseload. You can selectively transfer visual and audio models between
files, as well as transferring entire caseloads from one therapist to another. During a therapy session, you can
instantly replace the original model with the speaker's own "best
effort" production, in which case models from the library merely provide a
starting point for therapy, with operation otherwise adapted to meet the individual's
specific needs.
For
a more in depth look at VideoVoice, check-out the following URL

I PUT IN MY VOICE, SO WHERE’S THE
PICTURE?.